




Układy scalone IC w jednym miejscu kup EPM240T100C5N IC CPLD 192MC 4.7NS 100TQFP


Cechy produktu
| TYP | OPIS |
| Kategoria | Układy scalone (IC) Osadzony CPLD (złożone programowalne urządzenia logiczne) |
| Mfr | Intel |
| Seria | MAX® II |
| Pakiet | Taca |
| Standardowe opakowanie | 90 |
| Stan produktu | Aktywny |
| Programowalny typ | W programowalnym systemie |
| Czas opóźnienia tpd(1) Maks | 4,7 ns |
| Zasilanie napięciowe – wewnętrzne | 2,5 V, 3,3 V |
| Liczba elementów/bloków logicznych | 240 |
| Liczba makrokomórek | 192 |
| Liczba wejść/wyjść | 80 |
| temperatura robocza | 0°C ~ 85°C (TJ) |
| Typ mocowania | Montaż powierzchniowy |
| Opakowanie/etui | 100-TQFP |
| Pakiet urządzeń dostawcy | 100-TQFP (14×14) |
| Podstawowy numer produktu | EPM240 |
Koszt był jednym z głównych problemów stojących przed chipami pakowanymi 3D, a Foveros będzie pierwszą produkcją Intela na dużą skalę dzięki swojej wiodącej technologii pakowania.Intel twierdzi jednak, że chipy produkowane w obudowach 3D Foveros są niezwykle konkurencyjne cenowo w stosunku do standardowych konstrukcji chipów – a w niektórych przypadkach mogą nawet być tańsze.
Intel zaprojektował chip Foveros tak, aby był jak najtańszy i nadal spełniał założone przez firmę cele wydajnościowe – jest to najtańszy chip w pakiecie Meteor Lake.Intel nie podał jeszcze szybkości interkonektu/płytki bazowej Foveros, ale stwierdził, że komponenty mogą pracować z częstotliwością kilku GHz w konfiguracji pasywnej (oświadczenie sugerujące istnienie aktywnej wersji warstwy pośredniej, którą Intel już opracowuje ).Dlatego Foveros nie wymaga od projektanta pójścia na kompromis w zakresie ograniczeń przepustowości lub opóźnień.
Intel oczekuje również, że projekt będzie dobrze skalowany zarówno pod względem wydajności, jak i kosztów, co oznacza, że może oferować specjalistyczne projekty dla innych segmentów rynku lub warianty wersji o wysokiej wydajności.
Koszt zaawansowanych węzłów na tranzystor rośnie wykładniczo, w miarę jak procesy chipów krzemowych zbliżają się do granic swoich możliwości.A projektowanie nowych modułów IP (takich jak interfejsy I/O) dla mniejszych węzłów nie zapewnia dużego zwrotu z inwestycji.Dlatego ponowne wykorzystanie niekrytycznych płytek/chipletów w „wystarczająco dobrych” istniejących węzłach może zaoszczędzić czas, koszty i zasoby programistyczne, nie wspominając o uproszczeniu procesu testowania.
W przypadku pojedynczych układów Intel musi po kolei testować różne elementy układu, takie jak pamięć lub interfejsy PCIe, co może być procesem czasochłonnym.Dla kontrastu, producenci chipów mogą jednocześnie testować małe chipy, aby zaoszczędzić czas.Covery mają również tę zaletę, że projektują chipy dla określonych zakresów TDP, ponieważ projektanci mogą dostosowywać różne małe chipy do swoich potrzeb projektowych.
Większość z tych punktów brzmi znajomo i wszystkie są tymi samymi czynnikami, które sprowadziły AMD na ścieżkę chipsetów w 2017 roku. AMD nie było pierwszą firmą, która zastosowała konstrukcje oparte na chipsetach, ale była pierwszym dużym producentem, który zastosował tę filozofię projektowania do masową produkcję nowoczesnych chipów, do czego Intel wydaje się podejść nieco późno.Jednak proponowana przez firmę Intel technologia pakowania 3D jest znacznie bardziej złożona niż konstrukcja AMD oparta na organicznej warstwie pośredniej, co ma zarówno zalety, jak i wady.
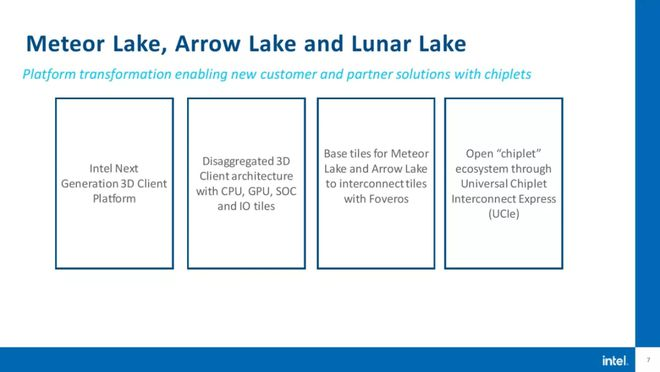
Różnica zostanie ostatecznie odzwierciedlona w gotowych chipach, a Intel twierdzi, że nowy chip 3D Meteor Lake będzie dostępny w 2023 r., a Arrow Lake i Lunar Lake w 2024 r.
Intel poinformował również, że oczekuje się, że chip superkomputera Ponte Vecchio, który będzie miał ponad 100 miliardów tranzystorów, stanie w sercu Aurory, najszybszego superkomputera na świecie.
-

XC7K325T-1FBG676I 676-FCBGA (27×27) zintegrowany...
-

IRLML6402TRPBF Nowy i oryginalny zintegrowany obwód...
-

IPD135N08N3G Zupełnie nowy układ scalony z...
-

Zupełnie nowy, oryginalny MOSFET TO-220-3 IRFB4321PBF
-

Układ scalony nowy i oryginalny elektron...
-

JXSQ Nowe i oryginalne chipy IC REG BUCK ADJ 3.5...